Problem
Public API data was easy to access but not ready for governed, repeatable reporting.
This example shows a repeatable path from API ingestion to governed reporting outputs, with clear separation between engine runtime and BI delivery.
Quick overview
Public API data was easy to access but not ready for governed, repeatable reporting.
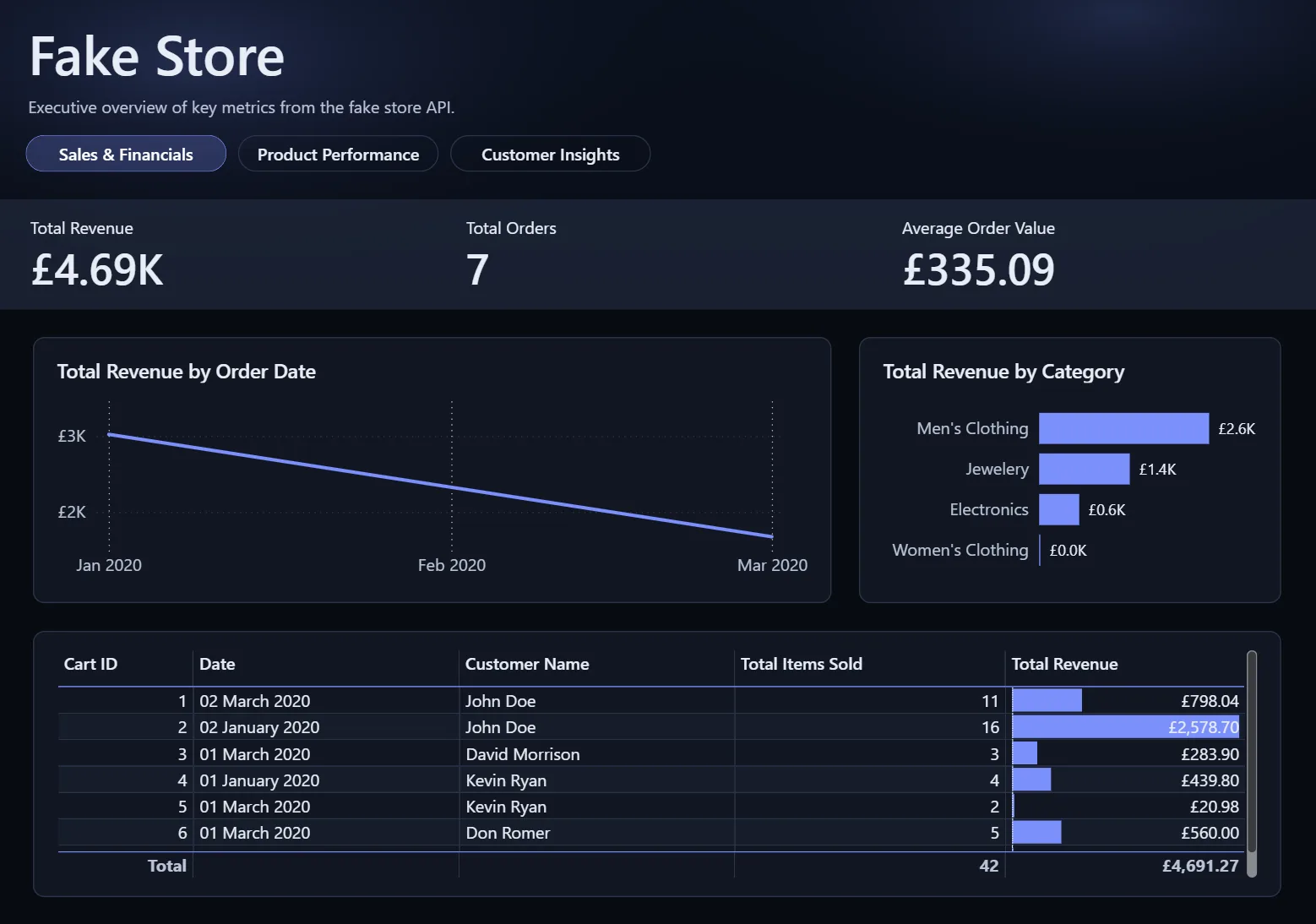
A reusable ingestion and modelling workflow with a reporting-ready retail star schema and Power BI outputs.
Reporting stays consistent because business logic lives in the model, not the dashboard.
A config-driven reference build using Axiomatic Engine, dbt-led transformation, and client-ownable delivery assets.
Reporting model
The Fake Store source data is reshaped into a reporting-ready star schema built for reuse across dashboards and analysis. Business logic sits in the model layer so metrics stay consistent across outputs.
The model separates cart-item facts from shared dimensions for products, customers, and dates. That makes the reporting layer easier to extend, test, and maintain.
| Table | Role | Grain | Purpose |
|---|---|---|---|
fct_cart_items | Core sales fact | One row per cart item | Supports revenue, quantity, and product analysis. |
dim_products | Product dimension | One row per product | Holds product attributes and category information. |
dim_users | Customer dimension | One row per user | Supports customer-level analysis and segmentation. |
dim_dates | Date dimension | One row per date | Supports time-based filtering and reporting. |
Delivery architecture
This diagram summarises the delivery flow from ingestion to warehouse modelling and then BI consumption.
For clients, this creates a reliable reporting foundation where pipeline changes and dashboard changes can be managed independently.
Consumption layer
Reporting assets are versioned separately from engine runtime code, so BI can evolve independently while staying aligned to the same warehouse contract.
The PBIX artefact, semantic model assets, and screenshots show how reporting consumes the governed model in practice.
Reproducibility
Open engine project repository
cd projects/fake_store && uv sync
cd projects/fake_store && uv run python run_pipeline.py --skip-transforms
cd projects/fake_store && uv run python run_pipeline.py --run-transformsTechnical delivery detail
This case study demonstrates a repeatable reporting workflow from API-first source data without embedding business logic in dashboards. It provides a clear handover between data engineering and BI delivery while keeping implementation evidence verifiable.
The engine layer defines ingestion, rerun behaviour, and transform contracts in versioned code.
projects/fake_store/run_pipeline.py.models/gold/schema.yml.projects/fake_store/.env.example.Reporting assets consume the same contract but are versioned separately from engine runtime code.
Model choices prioritise explicit grain, predictable reruns, and auditable quality checks.
merge for updates, replace for snapshots).This example is demonstration-focused but designed to show reproducible and verifiable delivery quality.